| Containers In Memory: How Big Is Big? | |||||
|
|
|
||||
|
|||||
| ||||||||||
|
| Containers In Memory: How Big Is Big?This article appeared in C/C++ Users Journal, 19(1), January 2001.
This column addresses two topics: An update on what's going on in the C++ standards process, and a technical question. For information about the former, see the accompanying "Standards Update" sidebar for breaking news about the 1998 C++ standard's first official update, whose ink should be drying as you read this, and how it affects you. The technical question is this: How much memory do the various standard containers use to store the same number of objects of the same type T? To answer this question, we have to consider two major items:
Let's begin with a brief recap of dynamic memory allocation and then work our way back up to what it means for the standard library. Memory Managers and Their Strategies: A Brief SurveyTo understand the total memory cost of using various containers, it's important to understand the basics of how the underlying dynamic memory allocation works - after all, the container has to get its memory from some memory manager somewhere, and that manager in turn has to figure out how to parcel out available memory by applying some memory management strategy. Here, in brief, are two popular memory management strategies. Further details are beyond the scope of this article; consult your favorite operating systems text for more information:
In practice, you'll often see combinations of the above. For example, perhaps your memory manager uses a general-purpose allocation scheme for all requests over some size S, and as an optimization provides a fixed-size allocation scheme for all requests up to size S. It's usually unwieldy to have a separate arena for requests of size 1, another for requests of size 2, and so on; what normally happens is that the manager has a separate arena for requests of multiples of a certain size, say 16 bytes. If you request 16 bytes, great, you only use 16 bytes; if you request 17 bytes, the request is allocated from the 32-byte arena, and 15 bytes are wasted. This is a source of possible overhead, but more about that in a moment. The obvious next question is, Who selects the memory management strategy? There are several possible layers of memory manager involved, each of which may override the previous (lower-level) one:
These levels are summarized in Figure 1.
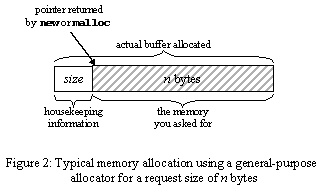
Thus memory allocators come in various flavours, and can or will vary from operating system to operating system, from compiler to compiler on the same operating system, from container to container - and even from object to object, say in the case of a vector<int> object which uses the strategy implemented by allocator<int>, and a vector<int, MyAllocator> object which could express-mail memory blocks from Taiwan unless it's a weekday night and the Mets are playing, or implement whatever other strategy you like. "I'll Take 'Operator New' For 200 Bytes, Alex"When you ask for n bytes of memory using new or malloc, you actually use up at least n bytes of memory because typically the memory manager must add some overhead to your request. Two common considerations that affect this overhead are: 1. Housekeeping overhead. In a general-purpose (i.e., not fixed-size) allocation scheme, the memory manager will have to somehow remember how big each block is so that it later knows how much memory to release when you call delete or free. Typically the manager remembers the block size by storing that value at the beginning of the actual block it allocates, and then giving you a pointer to "your" memory that's offset past the housekeeping information. (See Figure 2.) Of course, this means it has to allocate extra space for that value, which could be a number as big as the largest possible valid allocation and so is typically the same size as a pointer. When freeing the block, the memory manager will just take the pointer you give it, subtract the number of housekeeping bytes and read the size, then perform the deallocation.
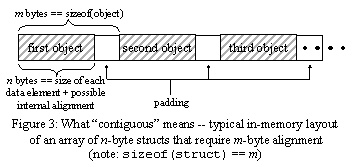
Of course, fixed-size allocation schemes (i.e., ones that return blocks of a given known size) don't need to store such overhead because they always know how big the block will be. 2. Chunk size overhead. Even when you don't need to store extra information, a memory manager will often reserve more bytes than you asked for because memory is often allocated in certain-sized chunks. For one thing, some platforms require certain types of data to appear on certain byte boundaries (e.g., some require pointers to be stored on 4-byte boundaries) and either break or perform more slowly if they're not. This is called alignment, and it calls for extra padding within, and possibly at the end of, the object's data. Even plain old built-in C-style arrays are affected by this need for alignment because it contributes to sizeof(struct). See Figure 3, where I distinguish between internal padding bytes and at-the-end padding bytes, although both contribute to sizeof(struct).
For example: // Example 1: Assume sizeof(long) == 4 and longs have a 4-byte In Figure 3's terms, n == 1 + 3 + 4 + 1 == 9, and m == sizeof(X1) == 12.[1] Note that all the padding contributes to sizeof(X1). The at-the-end padding bytes may seem odd, but are needed so that when you build an array of X1's one after the other in memory, the long data is always 4-byte aligned. This at-the-end padding is the padding that's the most noticeable, and the most often surprising for folks examining object data layout for the first time. It can be particularly surprising in this rearranged struct: struct X2 Now the data members really are all contiguous in memory (n == 6),[2] yet there's still extra space at the end that counts toward m == sizeof(X2) == 8 and that padding is most noticeable when you build an array of X2's. Bytes 6-7 are the padding highlighted in Figure 3. Incidentally, this is why when writing the standard it's surprisingly tricky to wordsmith the requirement that "vectors must be contiguous" in the same sense as arrays - in Figure 3, the memory is considered contiguous even though there are "gaps" of dead space, so what is "contiguous," really? Essentially, the individual sizeof(struct) chunks of memory are contiguous, and that definition works because sizeof(struct) already includes padding overhead. See also the "Standards Update" sidebar accompanying this article for more about contiguous vectors. The C++ standard guarantees that all memory allocated via operator new or malloc will be suitably aligned for any possible kind of object you might want to store in it, which means that operator new and malloc have to respect the strictest possible type alignment requirement of the native platform. Alternatively, as described earlier, a fixed-size allocation scheme might maintain memory arenas for blocks of certain sizes that are multiples of some basic size m, and a request for n bytes will get rounded up to the next multiple of m. Memory and the Standard Containers: The Basic StoryNow we can address the original question: How much memory do the various standard containers use to store the same number of elements of the same type T? Each standard container uses a different underlying memory structure and therefore imposes different overhead per contained object:
Table 1 summarizes this basic overhead for each container.
Table 1: Basic overhead per contained object for various containers Memory and the Standard Containers: The Real WorldNow we get to the interesting part: Don't be too quick to draw conclusions from Table 1. For example, judging from just the housekeeping data required for list and set, you might conclude that list requires less overhead per contained object than set - after all, list only stores two extra pointers, whereas set stores three. The interesting thing is that this may not be true once you take into consideration the runtime memory allocation policies. To dig a little deeper, consider Table 2 which shows the node layouts typically used internally by list, set/multiset, and map/multimap.
Table 2: Dynamic memory blocks used per contained object for various containers Next, consider what happens in the real world under the following assumptions, which happen to be drawn from a popular platform:
Table 3 contains a sample analysis with these numbers. You can try this at home; just plug in the appropriate numbers for your platform to see how this kind of analysis applies to your own current environment. To see how to write a program that figures out what the actual block overhead is for allocations of specific sizes on your platform, see Appendix 3 of Jon Bentley's classic Programming Pearls, 2nd edition.[4]
Table 3: Same actual overhead per contained object Looking at Table 3, we immediately spy one interesting result: For many cases - that is, for about 75% of possible sizes of the contained type T - list and set/multiset actually incur the same memory overhead in this particular environment. What's more, here's an even more interesting result: even list<char> and set<int> have the same actual overhead in this particular environment, even though the latter stores both more object data and more housekeeping data in each node. If memory footprint is an important consideration for your choice of data structure in specific situations, take a few minutes to do this kind of analysis and see what the difference really is in your own environment - sometimes it's less than you might think! SummaryEach kind of container chooses a different space/performance tradeoff. You can do things efficiently with vector and set that you can't do with list, such as O(log N) searching;[5] you can do things efficiently with vector that you can't do with list or set, such as random element access; you can do things efficiently with list, less so with set, and more slowly still with vector, such as insertion in the middle; and so on. To get more flexibility often requires more storage overhead inside the container, but after you account for data alignment and memory allocation strategies, the difference in overhead may be significantly different than you'd think! For related discussion about data alignment and space optimizations, see also Item 30 in Exceptional C++.[6] AcknowledgmentThanks to Pete Becker for the discussion that got me thinking about this topic.
Notes1. Only a perverse implementation would add more than the minimum padding. 2. The compiler isn't allowed to do this rearrangement itself, though. The standard requires that all data that's in the same public:, protected:, or private: must be laid out in that order by the compiler. If you intersperse your data with access specifiers, though, the compiler is allowed to rearrange the access-specifier-delimited blocks of data to improve the layout, which is why some people like putting an access specifier in front of every data member. 3. Laurence Marrie. "Algorithm Alley: Alternating Skip Lists" (Dr. Dobb's Journal, 25(8), August 2000). 4. Jon Bentley. Programming Pearls, 2nd edition (Addison-Wesley, 2000). 5. If the vector's contents are sorted. 6. Herb Sutter. Exceptional C++ (Addison-Wesley, 2000). 7. Herb Sutter. "Standard Library News, Part 1: Vectors and Deques" (C++ Report, 11(7), July/August 1999). 8. Herb Sutter. "When Is a Container Not a Container?" (C++ Report, 11(5), May 1999). |
Copyright © 2009 Herb Sutter |