| The String Formatters of Manor Farm | |||||
|
|
|
||||
|
|||||
| ||||||||||
|
| The String Formatters of Manor FarmThis article appeared in C/C++ Users Journal, 19(11), November 2001.
"All animals are equal, but some animals are more equal than others." - George Orwell, Animal Farm [1]
Consider the following C code that uses sprintf() to convert an integer value to a human-readable string representation, perhaps for output on a report or in a GUI window:
The $64,000 question[1] is: How would you do this kind of thing in C++? Well, all right, that's not quite the question because, after all, Example 1 is valid C++. The true $64,000 question is: Throwing off the shackles of the C90 standard [2] on which the C++98 standard [3] is based, if indeed they are shackles, isn't there a superior way to do this in C++ with its classes and templates and so forth? That's where the question gets interesting, because Example 1 is the first of no fewer than four direct, distinct, and standard ways to accomplish this task. Each of the four ways offers a different tradeoff among clarity, type safety, runtime safety, and efficiency. Moreover, to paraphrase George Orwell's revisionist pigs, 'all four choices are standard, but some are more standard than others' - and, to add insult to injury, not all of them are from the same standard. They are, in the order I'll discuss them:
Finally, as though that's not enough, there's a fifth not-yet-standard-but-liable-to-become-standard alternative for simple conversions that don't require special formatting:
Enough chat; let's dig in. Option #1: The Joys and Sorrows of sprintf()The code in Example 1 is just one example of how we might use sprintf(). I'm going to use Example 1 as a motivating case for discussion, but don't get too tied to this simple PrettyFormat() one-liner. Keep in mind the larger picture: We're interested in looking at how we would normally choose to format nonstring values as strings in the general case, perhaps in code that's more likely to change and grow over time than the simple case in Example 1. I'm going to list the major issues involved by analyzing sprintf() in more detail. sprintf() has two major advantages and three distinct disadvantages. The two advantages are as follows: Issue #1: Ease of use and clarity. Once you've learned the commonly used formatting flags and their combinations, using sprintf() is succinct and obvious, not convoluted. It says directly and concisely what needs to be said. For this, the printf() family is hard to beat in most text formatting work. (True, most of us still have to look up the more rarely-used formatting flags, but they are after all used rarely.) Issue #2: Maximum efficiency (ability to directly use existing buffers). By using sprintf() to put the result directly into an already-provided buffer, PrettyFormat() gets the job done without needing to perform any dynamic memory allocations or other extra off-to-the-side work. It's given an already-allocated place to put the output and puts the result directly there. Caveat lector: Of course, don't put too much weight on efficiency just yet; your application may well not notice the difference. Never optimize prematurely, but optimize only when timings show that you really need to do so. Write for clarity first, and for speed later if necessary. In this case, never forget that the efficiency comes at the price of memory management encapsulation -Issue #2 is phrased here as "you get to do your own memory management," but the flip side is "you have to do your own memory management"! Alas, as most sprintf() users know, the story doesn't end quite there. sprintf() also has these significant drawbacks: Issue #3: Length safety. Using sprintf() is a common source of buffer overrun errors if the destination buffer doesn't happen to be big enough for the whole output.[2] For example, consider this calling code:
In the above case, the value 42 happens to be small enough so that the five-byte result " 42\0" happens to fit into smallBuf. But the day the code changes to:
we'll start scribbling past the end of smallBuf, which may be into the bytes of value itself if the compiler chose a memory layout that put value immediately after smallBuf in memory. We can't easily make Example 1 much safer, though. True, we could change Example 1 to take the length of the buffer and then check sprintf()'s return value, which will tell after the fact how many bytes sprintf() ended up writing. This gives us something like:
That's no solution at all. By the time the error is detected the overrun has already occurred, we'll already have scribbled on someone else's bytes, and in bad cases our execution may never even get to the error-reporting code.[3] Issue #4: Type safety. For sprintf(), type errors are runtime errors, not compile-time errors, and they may not even manifest right away. The printf() family uses C's variable argument lists, and C compilers generally don't check the parameter types for such lists.[4] Nearly every C programmer has had the joy of finding out in subtle and not-so-subtle ways that they got the format specifier wrong, and all too often such errors are found only after a pressure-filled late-night debugging session spent trying to duplicate a mysterious crash reported by a key customer. Granted, the code in Example 1 is so trivial that it's likely easy enough to maintain now when we know we're just throwing a single int at sprintf(), but even so it's not hard to go wrong if your finger happens to hit something other than "d" by mistake. For example, "c" happens to be right next to "d" on most keyboards; if we'd simply mistyped the sprintf() call as
then we'd probably see the mistake quite quickly when the output is some character instead of a number, because sprintf() will silently reinterpret the first byte of i as a char value. Alternatively, "s" is also right next to "d", and if we'd mistyped it as
then we'd probably also catch the error quite quickly because the program is likely to crash immediately or at least intermittently. In this case sprintf() will silently reinterpret the integer as a pointer to char and then happily attempt to follow that pointer into some random region of memory. But here's a more subtle one: What if we'd instead mistyped "d" as "ld"?
In this case, the format string is telling sprintf() to expect a long int, not just an int, as the first piece of data to be formatted. This too is bad C code, but the trouble is that not only won't this be a compile-time error, but it might not even be a runtime error right away. On many popular platforms, the result will still be the same as before. Why? Because on many popular platforms ints happen to have the same size and layout as longs. You may not notice this error until you port the above code to a platform where int isn't the same size as long, and even then it might not always produce incorrect output or immediate crashes. Finally, consider a related issue. Issue #5: Templatability. It's very hard to use sprintf() in a template. Consider:
The best (worst?) you could do is declare the base template, and then provide specializations for all the types that are compatible with sprintf():
In summary, here's sprintf():
The other solutions we'll consider next choose different tradeoffs among these considerations. Option #2: snprintf()Of the other choices, sprintf()'s closest relative is of course snprintf(). snprintf() only adds only one new facility to sprintf(), but it's an important one: The ability to specify the maximum length of the output buffer, thereby eliminating buffer overruns. Of course, if the buffer is too small then the output will be truncated. snprintf() has long been a widely available nonstandard extension present on most major C implementations. With the advent of the C99 standard [4], snprintf() has "come out" and gone legit, now officially sanctioned as a standard facility. Until your own compiler is C99-compliant, though, you may have to use this under a vendor-specific extension name such as _snprintf(). Frankly, you should already have been using snprintf() over sprintf() anyway, even before snprintf() was standard. Calls to length-unchecked functions like sprintf() are banned in most good coding standards, and for good reason. The use of unchecked sprintf() calls has long been a notoriously common problem causing program crashes in general,[5] and security weaknesses in particular.[6] With snprintf(), we can correctly write the length-checked version we were trying to create earlier:
Note that it's still possible for the caller to get the buffer length wrong. That means snprintf() still isn't as 100% bulletproof for overflow-safety as the later alternatives that encapsulate their own resource management, because, but it's certainly lots safer and deserves a "Yes" under the "Length safe?" question. With sprintf() we have no good way to avoid for certain the possibility of buffer overflow; with snprintf() we can ensure it doesn't happen. Note that some pre-standard versions of snprintf() behaved slightly differently. In particular, under one major implementation, if the output fills or would overflow the buffer then the buffer is not zero-terminated. On such environments, the function would need to be written slightly differently to account for the nonstandard behavior:
In every other way, sprintf() and snprintf() are the same. In summary, here's how snprintf() compares to sprintf():
Guideline: Never use sprintf(). If you decide to use C stdio facilities, always use length-checked calls like snprintf() even if they're only available as a nonstandard extension on your current compiler. There's no drawback, and there's real benefit, to using snprintf() instead. When I presented this material as part of a talk at Software Development East in Boston this summer [2001], I was shocked to discover that only about ten percent of the class had heard of snprintf(). But one of those who had immediately put up his hand to describe how, on his current project, they'd recently discovered a few buffer-overrun bugs, globally replaced sprintf() with snprintf() throughout the project, and found during testing that not only were those bugs gone but suddenly several other mysterious bugs had also disappeared - bugs that had been reported for years but that the team hadn't been able to diagnose. As I was saying: Never use sprintf(). Option #3: std::stringstreamThe most common facility in C++ for stringizing data is the stringstream family. Here's what Example 1 would look like using an ostringstream instead of sprintf():
Using stringstream exchanges the advantages and disadvantages of sprintf(). Where sprintf() shines, stringstream does less well: Issue #1: Ease of use and clarity. Not only has one line of code turned into three, but we've needed to introduce a temporary variable. This version of the code is superior in several ways, but code clarity isn't one of them. It's not that the manipulators are hard to learn - they're as easy to learn as the sprintf() formatting flags - but that they're generally more clumsy and verbose. I find that code littered with long names like << setprecision(9) and << setw(14) all over the place is a bear to read (compared to, say, %14.9), even when all of the manipulators are arranged reasonably well in columns. Issue #2: Efficiency (ability to directly use existing buffers). A stringstream does its work in an additional buffer off to the side, and so will usually have to perform extra allocations for that working buffer and for any other helper objects it uses. I tried the Example 3 code on two popular current compilers and instrumented ::operator new() to count the allocations being performed. One platform performed two dynamic memory allocations, and the other performed three. Where sprintf() breaks down, however, stringstream glitters: Issue #3: Length safety. The stringstream's internal basic_stringbuf buffer automatically grows as needed to fit the value being stored. Issue #4: Type safety. Using operator<<() and overload resolution always gets the types right, even for user-defined types that provide their own stream insertion operators. No more obscure runtime errors because of type mismatches. Issue #5: Templatability. Now that the right operator<<() is automatically called, it's trivial to generalize PrettyFormat() to operate on arbitrary data types:
In summary, here's how stringstream compares to sprintf():
Option #4: std::strstreamFairly or not, strstream is something of a persecuted pariah. Because it has been deprecated in the C++98 standard, the top C++ books at best cover it briefly [7], mostly ignore it [8], or even explicitly state they won't cover it because of its official second-string status [9]. Although deprecated because the standards committee felt it was superseded by stringstream, which better encapsulates memory management, strstream is still an official part of the standard that conforming C++ implementers must provide.[7] Because strstream is still standard, it deserves mention here too for completeness. It also happens to provide a useful mix of strengths. Here's what Example 1 might look like using strstream:
Issue #1: Ease of use and clarity. strstream comes in slightly behind stringstream when it comes to ease of use and code clarity. Both require a temporary object to be constructed. With strstream you have to remember to tack on an ends to terminate the string, which I dislike. If you forget to do this then you are in danger of overrunning the end of the buffer when reading it afterwards if you're relying on its being terminated by a null character; even sprintf() isn't this fragile, and always tacks on the null. But at least using strstream in the manner shown in Example 4 doesn't require calling a .str() function to extract the result at the end. (Of course, alternatively, if you let strstream create its own buffer, the memory is only partly encapsulated; you will need not only a .str() call at the end to get the result out, but also a .freeze(false) else the strstreambuf won't free the memory.) Issue #2: Efficiency (ability to directly use existing buffers). By constructing the ostrstream object with a pointer to an existing buffer, no extra allocations at all need be performed; the ostrstream will store its result directly in the output buffer. This is an important divergence from stringstream, which offers no comparable facility for placing the result directly in an existing destination buffer and thereby avoid extra allocation.[8] Of course, ostrstream can alternatively use its own dynamically allocated buffer if you don't have one handy already; just use ostrstream's default constructor instead.[9] Indeed, strstream is the only one of the options covered here that gives you this choice. Issue #3: Length safety. As used in Example 4, the ostrstream's internal strstreambuf buffer automatically checks its length to make sure it doesn't write beyond the end of the supplied buffer. If instead we had used a default-constructed ostrstream, its internal strstreambuf buffer would automatically grow as needed to fit the value being stored. Issue #4: Type safety. Fully type-safe, just like stringstream. Issue #5: Templatability. Fully templatable, just like stringstream. For example:
In summary, here's how strstream compares to sprintf():
It's, um, slightly embarrassing that the deprecated facility shows so strongly in this side-by-side comparison, but that's life. Option #5: boost::lexical_castIf you haven't yet discovered Boost at www.boost.org, my advice is to discover it. It's a public library of C++ facilities that's written principally by C++ standards committee members. Not only is it good peer-reviewed code written by experts and in the style of the C++ standard library, but these facilities are explicitly intended as candidates for inclusion in the next C++ standard and are therefore worth getting to know. Besides, you can freely use them today. One of the facilities provided in the Boost libraries is boost::lexical_cast, which is a handy wrapper around stringstream. Indeed, Kevlin Henney's code is so concise and elegant that I can present it here in its entirety (minus workarounds for older compilers):
Note that lexical_cast is not intended to be a direct competitor for the more general string formatter sprintf(). Instead, lexical_cast is for converting data from one streamable type to another, and it competes more directly with C's atoi() et al. conversion functions as well as with the nonstandard but commonly available itoa() et al. functions. It's close enough, however, that it definitely would be an omission not to mention it here. Here's what Example 1 would look like using lexical_cast, minus the at-least-four-character requirement:
Issue #1: Ease of use and clarity. This code embodies the most direct expression of intent of any of these examples. Issue #2: Efficiency (ability to directly use existing buffers). Since lexical_cast uses stringstream, it's no surprise that it needs at least as many allocations as stringstream. On one of the platforms I tried, Example 5 performed one more allocation than the plain stringstream version presented in Example 3; on the other platform, it performed no additional allocations over the plain stringstream version. Like stringstream, in terms of length safety, type safety, and templatability, lexical_cast shows very strongly. In summary, here's how lexical_cast compares to sprintf():
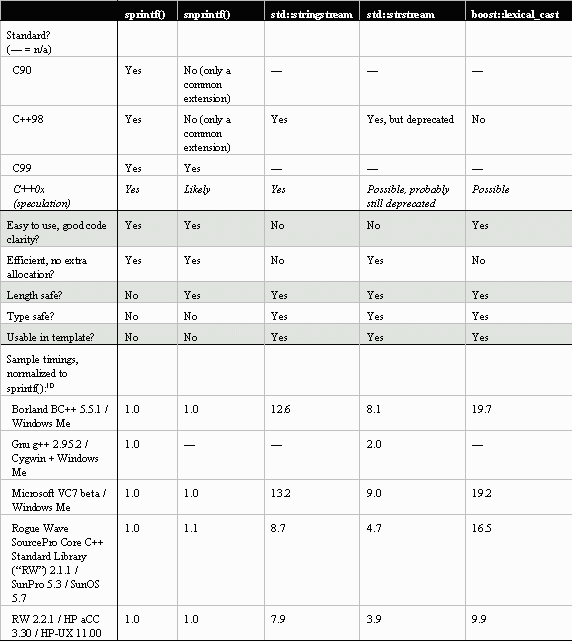
SummaryThere are issues we've not considered in detail. For example, all the string formatting herein has been to normal narrow char-based strings, not wide strings. We've also focused on the ability to gain efficiency by using existing buffers directly in the case of sprintf(), snprintf(), and strstream, but the flip side to "you get to do your own memory management" is "you have to do your own memory management" and the better encapsulation of memory management offered by stringstream, strstream, and lexical_cast may matter to you. (No typo, strstream is in both lists; it depends how you want to use it.) Putting it all together, we get the side-by-side comparison summarized in Table 1. Given the considerations we're using to judge the relative merits of each solution, there is no clear unique one-size-fits-all winner for all situations. From Table 1 I'll extract the following guidelines, also summarized in Table 2: · If all you're doing is converting a value to a string (or, for that matter, to anything else!): Prefer using boost::lexical_cast by default. · For simple formatting, or where you need wide string support or templatability: Prefer using stringstream or strstream; the code will be more verbose and harder to grasp than it would be with snprintf(), but for simple formatting it won't be too bad. · For more complex formatting, and where you don't need wide string support or templatability: Prefer using snprintf(). Just because it's C doesn't mean it's off limits to C++ programmers! · Only if actual performance measurements show that any of the above is really a bottleneck at a specific point in your code: In those isolated cases only, instead of the above consider using whichever one of the faster alternatives strstream or snprintf() makes sense. · Never use sprintf(). Finally, a last word about the pariah strstream: It offers an interesting combination of features, not the least of which being that it's the only option that allows you to choose whether to do your own memory management or to let the object (partly) encapsulate it. Its lone technical drawback is that of being somewhat fragile to use because of the ends issue and the memory management approach; its only other drawback is social stigma, because it's been shunted aside and doesn't get invited to parties much any more, and you should be aware that there's a slight possibility that both the standards committee and your compiler/library vendor may really take it away from you at some time in the future. It's a bit strange to see a deprecated feature showing so well. Although a particular animal may have distinct merits, even in the standard some animals are more equal than others…
Table 1: C and C++ string formatting alternatives
Table 2: Guideline summary AcknowledgmentsThanks to Jim Hyslop and the participants in the ACCU discussion thread about sprintf() that got me thinking about this topic, to Martin Sebor of Rogue Wave Software for the non-Windows timing results, and to Bjarne Stroustrup, Scott Meyers, Kevlin Henney, and Chuck Allison for their comments on drafts of this article. References[1] George Orwell. Animal Farm (Signet Classic, 1996, ISBN 0451526341). [2] ISO/IEC 9899:1990(E), Programming Languages - C (ISO C90 and ANSI C89 standard). [3] ISO/IEC 14882:1998(E), Programming Languages - C++ (ISO and ANSI C++ standard). [4] ISO/IEC 9899:1999(E), Programming Languages - C (ISO and ANSI C99 standard). [5] Kevlin Henney. C++ BOOST lexical_cast, http://www.boost.org/libs/conversion/lexical_cast.htm. [6] Bjarne Stroustrup. "Learning Standard C++ as a New Language" (C/C++ Users Journal, 17(5), May 1999). [7] Nicolai Josuttis. The C++ Standard Library (Addison-Wesley, 1999), page 649. [8] Bjarne Stroustrup. The C++ Programming Language, Special Edition (Addison-Wesley, 2000), page 656. [9] Angelika Langer and Klaus Kreft. Standard C++ IOStreams and Locales (Addison-Wesley, 2000), page 587. Notes1. Remember that, when the phrase was coined, $64,000 was enough to buy several houses and/or retire. 2. A common beginner's error is to rely on the width specifier, here "4", which doesn't work because the width specifier dictates a minimum width, not a maximum width. 3. Note that in some cases you can mitigate the buffer length problem by creating your own formats at runtime. As Bjarne Stroustrup puts it in [6], speaking of a similar case:
4. Using lint-like tools will help to catch this kind of error. 5. This is a real problem, and not just with sprintf() but with all length-unchecked calls in the standard C library. As John Nagle put it in news:comp.lang.c++.moderated on September 17, 2001: "Click on this link to bring up all web pages which mention "strcpy" and "buffer overflow". http://www.google.com/search?q=strcpy+%22buffer+overflow%22. Top items:
6. For example, for years it was fashionable for malicious web servers to crash web browsers by sending them very long URLs that were likely to be longer than the web browser's internal URL string buffer. Browsers that didn't check the length before copying into the fixed-length buffer ended up writing past the end of the buffer, usually overwriting data but in some cases overwriting code areas with malicious code that could then be executed. It's surprising just how much software out there was, and is, using unchecked calls. The previous footnote's partial list of popular buffer bugs includes several security-related issues. [Later note: Timing sure is weird sometimes, and everything old is new again. I wrote the above in mid-August, when the Code Red II worm was all over the press, but only later did I notice Microsoft's description of the security vulnerability Code Red II exploited: "A security vulnerability results because idq.dll contains an unchecked buffer in a section of code that handles input URLs. An attacker who could establish a web session with a server on which idq.dll is installed could conduct a buffer overrun attack and execute code on the web server." Haven't we learned this lesson yet? (Here's the URL)] 7. What does "deprecated" mean, in theory and in practice? When it comes to standards, "deprecated" denotes a feature that the committee warns you may disappear anytime in the future, possibly as soon as the next revision of the standard. To deprecate a feature amounts to "normative discouragement" - it's the strongest thing the committee can do to discourage you from using a feature without actually taking the feature away from you immediately. In practice, it's hard to remove even the worst deprecated features because, once the feature appears in a standard, people write code that depends on the feature - and every standards body is loath to break backward compatibility. Even when a feature is removed, implementers often continue to supply it because they, too, are loath to break backward compatibility. Oftentimes, deprecated features never do disappear from the standard. Standard Fortran, for example, still has features that have been deprecated for decades. 8. stringstream does offer a constructor that takes a string&, but it simply takes a copy of the string's contents instead of directly using the supplied string as its work area. 9. In Table 1's performance measurements, strstream shows unexpectedly poorly on two platforms, BC++ 5.5.1 and VC7 beta. The reason appears to be that on those implementations for some reason some allocations are always performed on each call to Example 4's PrettyFormat() (although both implementations still actually do perform fewer allocations when given an existing buffer to work with, as is done in Example 4, than when the strstream has to make its own buffer). The other environments, as expected, perform no allocations. 10. Sample results reporting the average of three runs each of which performs 1,000,000 calls to the corresponding Example code. Results may vary with other compiler versions and switch settings. |
Copyright © 2009 Herb Sutter |